单线程、多线程和协程的爬虫性能对比
豆瓣深圳影讯爬虫
文章目录
大家好,我是小小明。今天我要给大家分享的是如何爬取豆瓣上深圳近期即将上映的电影影讯,并分别用普通的单线程、多线程和协程来爬取,从而对比单线程、多线程和协程在网络爬虫中的性能。
具体要爬的网址是:https://movie.douban.com/cinema/later/shenzhen/
除了要爬入口页以外还需爬取每个电影的详情页,具体要爬取的结构信息如下:
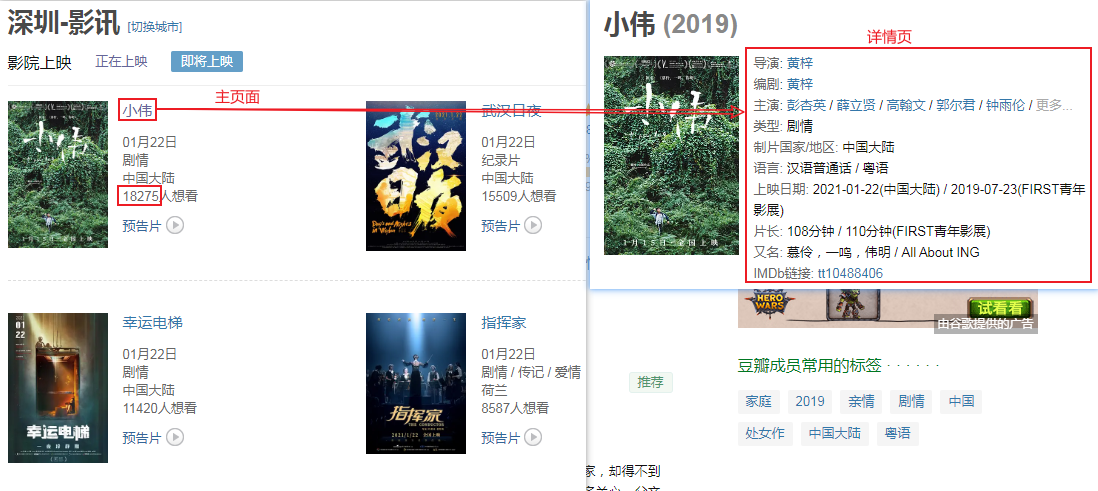
爬取测试
下面我演示使用xpath解析数据。
入口页数据读取:
1 | |
结果:
1 | |
检查一下所需数据的xpath:
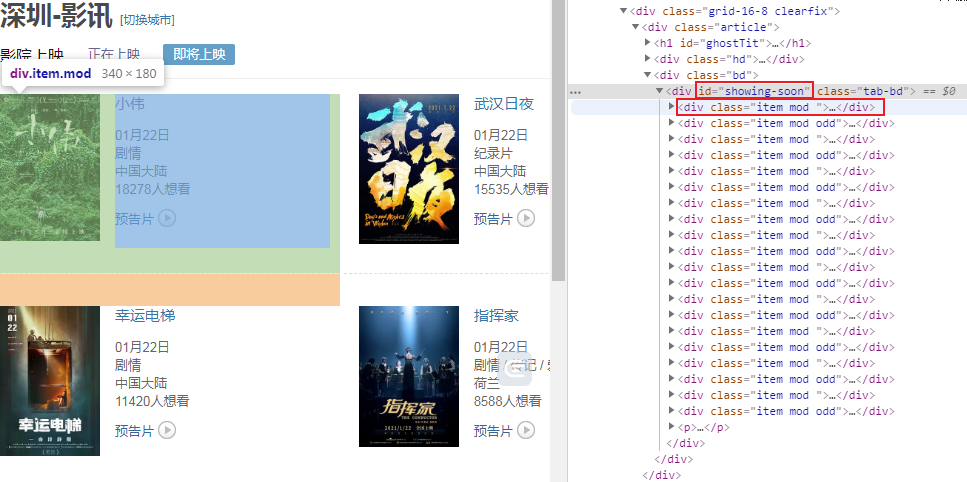
可以看到每个电影信息都位于id为showing-soon下面的div里面,再分别分析内部的电影名称、url和想看人数所处的位置,于是可以写出如下代码:
1 | |
结果:
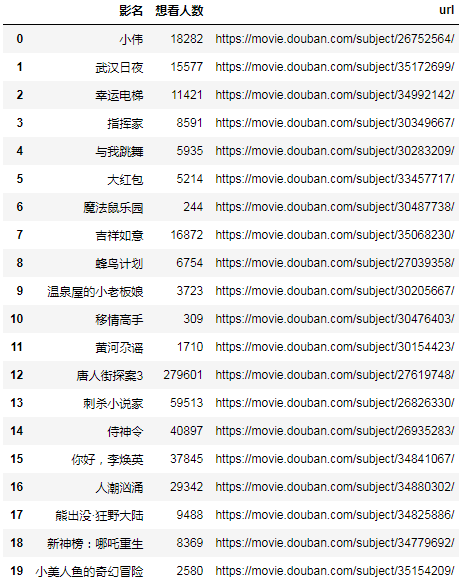
然后再选择一个详情页的url进行测试,我选择了熊出没·狂野大陆这部电影,因为文本数据相对最复杂,也最具备代表性:
1 | |
结果:
1 | |
分析详情页结构:
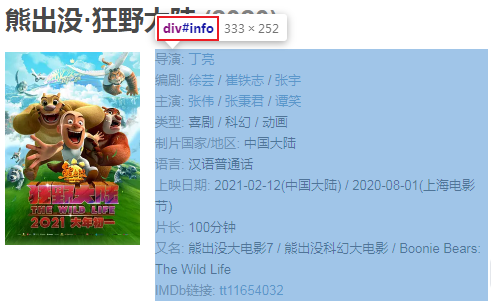
文本信息都在这个位置中,下面我们直接提取这个div下面的所有文本节点:
1 | |
结果:
1 | |
为了阅读方便,拼接一下:
1 | |
结果:
1 | |
接下来就简单了:
1 | |
结果:
1 | |
可以看到成功的切割出了每一项。
下面根据上面的测试基础,我们完善整体的爬虫代码:
单线程爬虫
1 | |
结果:
1 | |
爬到的文件:
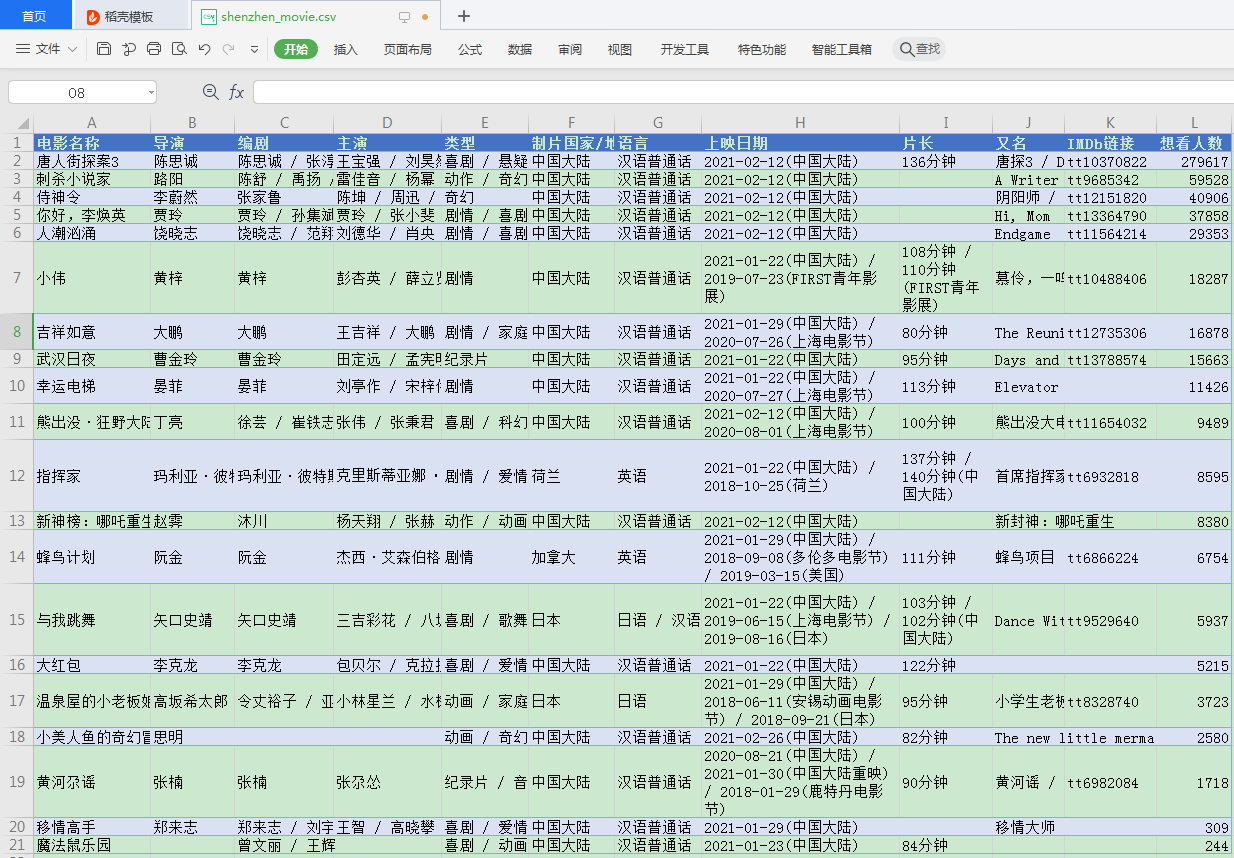
整体耗时:
42.5秒。
多线程爬虫
单线程的爬取耗时还是挺长的,下面看看使用多线程的爬取效率:
1 | |
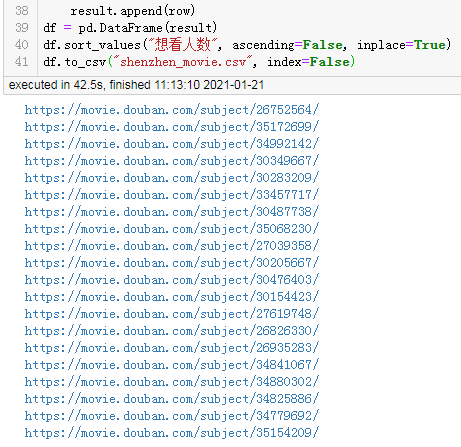
结果:
耗时8秒。
由于每个子页面都是单独的线程爬取,每个线程几乎都是同时在工作,所以最终耗时仅取决于爬取最慢的子页面。
协程异步爬虫
由于我在jupyter中运行,为了使协程能够直接在jupyter中直接运行,所以我在代码中增加了下面两行代码,在普通编辑器里面可以去掉:
1 | |
这个问题是因为jupyter所依赖的高版本Tornado存在bug,将Tornado退回到低版本也可以解决这个问题。
下面我使用协程来完成这个需求的爬取:
1 | |
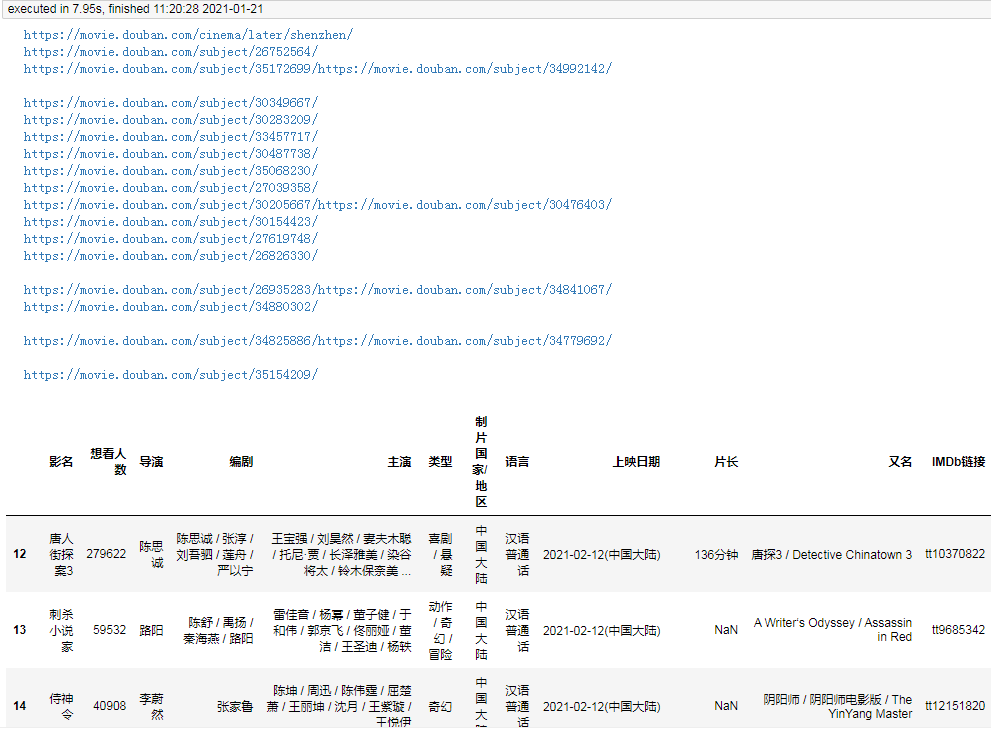
结果:

耗时仅7秒,相对比多线程更快一点。
由于request库不支持协程,所以我使用了支持协程的aiohttp进行页面抓取。当然实际爬取的耗时还取绝于当时的网络,但整体来说,协程爬取会比多线程爬虫稍微快一些。
回顾
今天我向你演示了,单线程爬虫、多线程爬虫和协程爬虫。可以看到一般情况下协程爬虫速度最快,多线程爬虫略慢一点,单线程爬虫则必须上一个页面爬取完成才能继续爬取。
但协程爬虫相对来说并不是那么好编写,数据抓取无法使用request库,只能使用aiohttp。所以在实际编写爬虫时,我们一般都会使用多线程爬虫来提速,但必须注意的是网站都有ip访问频率限制,爬的过快可能会被封ip,所以一般我们在多线程提速的同时使用代理ip来并发的爬取数据。
彩蛋:xpath+pandas解析表格并提取url
我们在深圳影讯的底部能够看到一个> 查看全部即将上映的影片的按钮,点进去能够看到一张完整近期上映电影的列表,发现这个列表是个table标签的数据:
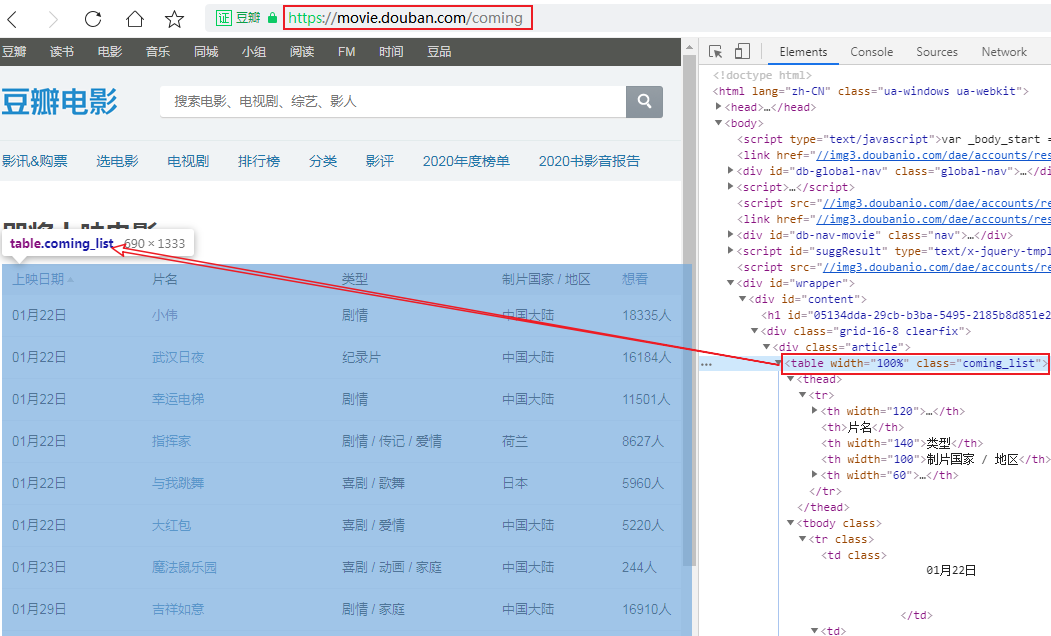
那就简单了,解析table我们可能压根就不需要用xpath,直接用pandas即可,但片名中包含的url地址还需解析,所以我采用xpath+pandas来解析这个网页,看看我的代码吧:
1 | |
结果:
| 上映日期 | 片名 | 类型 | 制片国家 / 地区 | 想看 | url | |
|---|---|---|---|---|---|---|
| 0 | 01月22日 | 小伟 | 剧情 | 中国大陆 | 18340人 | https://movie.douban.com/subject/26752564/ |
| 1 | 01月22日 | 武汉日夜 | 纪录片 | 中国大陆 | 16208人 | https://movie.douban.com/subject/35172699/ |
| 2 | 01月22日 | 幸运电梯 | 剧情 | 中国大陆 | 11504人 | https://movie.douban.com/subject/34992142/ |
| 3 | 01月22日 | 指挥家 | 剧情 / 传记 / 爱情 | 荷兰 | 8629人 | https://movie.douban.com/subject/30349667/ |
| 4 | 01月22日 | 与我跳舞 | 喜剧 / 歌舞 | 日本 | 5960人 | https://movie.douban.com/subject/30283209/ |
| 5 | 01月22日 | 大红包 | 喜剧 / 爱情 | 中国大陆 | 5221人 | https://movie.douban.com/subject/33457717/ |
| 6 | 01月23日 | 魔法鼠乐园 | 喜剧 / 动画 / 家庭 | 中国大陆 | 244人 | https://movie.douban.com/subject/30487738/ |
| 7 | 01月29日 | 吉祥如意 | 剧情 / 家庭 | 中国大陆 | 16914人 | https://movie.douban.com/subject/35068230/ |
| 8 | 01月29日 | 蜂鸟计划 | 剧情 | 加拿大 | 6780人 | https://movie.douban.com/subject/27039358/ |
| 9 | 01月29日 | 温泉屋的小老板娘 | 动画 / 家庭 | 日本 | 3736人 | https://movie.douban.com/subject/30205667/ |
| 10 | 01月29日 | 移情高手 | 喜剧 / 爱情 | 中国大陆 | 308人 | https://movie.douban.com/subject/30476403/ |
| 11 | 01月30日 | 黄河尕谣 | 纪录片 / 音乐 | 中国大陆 | 1742人 | https://movie.douban.com/subject/30154423/ |
| 12 | 02月12日 | 唐人街探案3 | 喜剧 / 悬疑 | 中国大陆 | 279735人 | https://movie.douban.com/subject/27619748/ |
| 13 | 02月12日 | 刺杀小说家 | 动作 / 奇幻 / 冒险 | 中国大陆 | 59601人 | https://movie.douban.com/subject/26826330/ |
| 14 | 02月12日 | 侍神令 | 奇幻 | 中国大陆 | 40954人 | https://movie.douban.com/subject/26935283/ |
| 15 | 02月12日 | 你好,李焕英 | 剧情 / 喜剧 | 中国大陆 | 37921人 | https://movie.douban.com/subject/34841067/ |
| 16 | 02月12日 | 人潮汹涌 | 剧情 / 喜剧 / 犯罪 | 中国大陆 | 29401人 | https://movie.douban.com/subject/34880302/ |
| 17 | 02月12日 | 熊出没·狂野大陆 | 喜剧 / 科幻 / 动画 | 中国大陆 | 9499人 | https://movie.douban.com/subject/34825886/ |
| 18 | 02月12日 | 新神榜:哪吒重生 | 动作 / 动画 / 奇幻 | 中国大陆 | 8408人 | https://movie.douban.com/subject/34779692/ |
| 19 | 02月26日 | 小美人鱼的奇幻冒险 | 动画 / 奇幻 / 冒险 | 中国大陆 | 2580人 | https://movie.douban.com/subject/35154209/ |
| 20 | 03月12日 | 北京爱情图鉴 | 剧情 | 中国大陆 | 1259人 | https://movie.douban.com/subject/27067713/ |
| 21 | 04月01日 | 来都来了 | 喜剧 | 中国大陆 | 1298人 | https://movie.douban.com/subject/34670706/ |
| 22 | 04月02日 | 我的姐姐 | 剧情 | 中国大陆 | 6427人 | https://movie.douban.com/subject/35158160/ |
| 23 | 04月30日 | 古董局中局 | 剧情 / 悬疑 / 冒险 | 中国大陆 | 16121人 | https://movie.douban.com/subject/26996619/ |
| 24 | 05月01日 | 秘密访客 | 剧情 / 悬疑 | 中国大陆 | 42302人 | https://movie.douban.com/subject/30378158/ |
| 25 | 05月01日 | 阳光劫匪 | 剧情 / 喜剧 / 奇幻 | 中国大陆 | 5974人 | https://movie.douban.com/subject/26933158/ |
| 26 | 05月01日 | 西游记之再世妖王 | 喜剧 / 动画 / 奇幻 | 中国大陆 | 3137人 | https://movie.douban.com/subject/26818326/ |
| 27 | 05月20日 | 你的婚礼 | 爱情 | 中国大陆 | 7148人 | https://movie.douban.com/subject/34973399/ |
| 28 | 07月01日 | 革命者 | 剧情 / 历史 | 中国大陆 | 740人 | https://movie.douban.com/subject/35288767/ |
| 29 | 07月01日 | 1921 | 剧情 / 历史 | 中国大陆 | 4人 | https://movie.douban.com/subject/35125443/ |
| 30 | 2022年02月01日 | 我心飞扬 | 剧情 / 传记 | 中国大陆 | 756人 | https://movie.douban.com/subject/32712599/ |
这样就能到了主页面的完整数据,再简单的处理一下即可。